Дубли страниц. Дубли страниц: что это, чем вредны, как найти и убрать. Чем опасны дубли страниц
Мы разговаривали про дубли страниц сайта replytocom. Напомню суть прошлой статьи. Она в том, то не следует делать закрытым в Роботсе путь чему-либо на вашем блоге. Желательно наоборот, роботс сделать открытым, чтобы робот зашел, посмотрел, увидел тег и не стал индексировать дубли страниц.
Если же данные копии страниц будут закрыты, данный робот скорее всего подобные дубли наоборот проиндексирует. Желательно это запомнить! Далее давайте вспомним, как мы искали копии реплитоком в поисковике Гугл. Я напомню:
site:ваш сайт replytocom , т.е. на примере моего это будет выглядеть site:сайт replytocom
Как искать дубли страниц на вашем блоге
Отлично. Сейчас мы поищем прочие копии страничек, а подробнее копии: feed, category, tag, comment-page, page, trackback, attachment_id, attachment
Их поиск проводим похожим образом, как мы искали дубли страниц реплитоком. Делаем все подобным образом, а именно зайдем в и внесем в поисковик любой блог, например site:realnodengi.ru feed

Нажав «Показ скрытых результатов» мы увидим:


22 дубля страницы. Что значит feed? Это непонятный отросток в конце адреса статьи. Для любого вашего поста жмете ctr + u и скорее всего увидите ссылочку feed в конце. Другими словами, подобные ссылки необходимо удалять. Давайте войдем в роботс данного сайта, мы увидим:

То есть то, что нам не нужно . Что же нам делать, подобные запрещения в роботсе желательно удалить. Что бы робот на них не заходил и не индексировал их на «всякий случай».
Отлично! Мы сделали проверку страничек feed.
Возьмём другой сайт, например reall-rabota.ru и вставим page. У нас получится site:reall-rabota.ru page:

Мы видим, что на данном сайте присутствует 61 дубль страниц page. От них необходимо избавляться. Я надеюсь, авторы данных блогов за анализ на меня не в обиде?
Подобный анализ проведите для своих блогов, и не только по данным копиям, но и по прочим, которые я приводил выше, таким как — category, tag и пр.
Ну как? Ваш результат вас порадовал?
Скорее всего не по всем данным словам вы найдете копии. Это конечно отлично! Но от тех, которые у вас имеются, придется избавиться! Давайте подумаем как?
Как убрать дубли страниц сайта решение проблемы
Во-первых , зайдите в мой роботс и скопируйте его себе, соответственно заменив сайт на название вашего сайта. Заменили? Отлично! Я думаю на многих блогах присутствовали запреты, как на сайте, приведенном выше.
Во вторых , перепишите следующие строки в ваш файлик.htaccess:

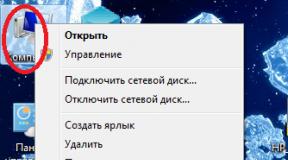
 Данный файл находится в вашей корневой папке, которая чаще всего называется public_html. Для этого я обычно открываю программу , переношу нужный файл на рабочий стол, открываю данный файлик софтом Notepad + +, вношу необходимые изменения и заменяю старый файл на новый.
Данный файл находится в вашей корневой папке, которая чаще всего называется public_html. Для этого я обычно открываю программу , переношу нужный файл на рабочий стол, открываю данный файлик софтом Notepad + +, вношу необходимые изменения и заменяю старый файл на новый.
После закачки нового файла ваш.htaccess должен получиться примерно таким:

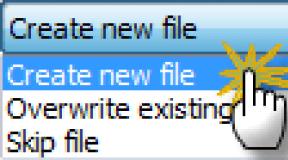
В третьих , вставляем в function.php после /*** ДОБАВЛЯЕМ meta robots noindex,nofollow ДЛЯ СТРАНИЦ ***/ function my_meta_noindex () { if (is_paged() // Все и любые страницы пагинации) {echo "".""."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем свой noindex, nofollow в head
В четвертых , проходим в расширение All in One Seo Pack и делаем так:

Если у вас другой плагин, например SEO, поставьте noindex в разделах, похожих по смыслу.
В пятых , в «Параметрах» идем в «Настройки-Обсуждения» и удаляем галку с пунктика Разбития комментариев:


В заключение предлагаю подробное видео про дубли.
На этом не всё, существует ещё множество дублей страниц и прочего хлама. Его необходимо удалять. Самому это не всегда сделать просто, поэтому иногда необходимо обращаться к профессионалу. Но его не всегда найдешь, да и не станешь постоянно обращаться.
Отсюда, желательно все тонкости узнать самому. Это можно сделать как при лично общении, так и изучив материал. Я имею в виду видеокурс. На мой взгляд, видеокурс предпочтительнее, т.к. вы пройдете обучение дама перед своим монитором!

Я не просто так привел данный курс, я его изучил. Мне лично он понравился. Раньше, Яндекс показывал у меня проиндексированных страниц 1220, хотя реально их 250. Сейчас, после очистки, Яндекс показывает 490, Гугл 530. Согласитесь, данные цифры ближе к реальным!
Но, как это не покажется странным, на большом количестве сайтов данные цифры зашкаливают за 200000 дублей и более. Без всяких шуток! Сайты с подобными показателями в скором времени могут быть забанены поисковиком. Но давайте вернемся к курсу. Приведу слова Александра:
Подробнее обо всём этом на сайте Борисова, для этого просто кликните по картинке с курсом.
В основном работа проделана, дубли страниц будут удалены после индексации, но не сразу, вам придется подождать несколько месяцев! Успехов в продвижении вашего ресурса! Если вам известны другие способы, как убрать дубли страниц сайта, пишите в комментариях, изучим вместе!
Анекдот в каждой статье.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
![]()
Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т. д. Поэтому дубли нужно быстро удалять и стараться не допускать их появления.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом
(CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи. В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические раздел
ы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y - Человеческий фактор . Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки
. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
site.ru/tools/tools/tools/…/…/…
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.

Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel="canonical". В код каждого дубля внедряется тег в виде
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.
Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
Отчет группирует страницы на четыре группы уникальности. Разбиение происходит по степени схожести. Дополнительно приводится статистика заполнения страницы текстовым контентом.
Дубли страниц, возникающие на сайте мешают эффективному продвижению портала. После создания ресурса следует как можно скорее избавится от таких помех и предотвратить их появление в процессе работы.
Дубль — это отдельная страница (документ) портала, контент которой полностью или частично совпадает с размещенной информацией. Данные могут задваиваться по нескольким причинам. Среди них:
- Искусственное создание владельцем страниц для выполнения ряда функций. Примером могут служить печатные формы для копирования информации о товаре/услуге.
- Генерация движком. CMS создает дубль, имеющий отличающийся адрес и расположенный в другой директории.
- Ошибки веб-мастера, управляющего ресурсом. Например, портал может иметь две одинаковые главные страницы с разными url («имя.ru» и «имя.ru/index.php»).
По вышеуказанным причинам возникает четкий дубль. Кроме этого, может происходить частичное задваивание контента. Такими небольшими помехами являются страницы, имеющие общую часть шаблона портала и отличающиеся небольшим наполнением (результатами поиска или отдельными элементами статьи).
Поиск дублей страниц сайта — необходимое мероприятие для предупреждения различных ошибок и проблем, связанных с продвижением в поисковых системах.
Проверить дубли страниц

Их отчета вы узнаете количество уникальны страниц, доля дублирующего контента, количество слов и грамматических ошибок на странице. Группы можно сортировать.
По окончанию анализа сервис сформирует отчет, в котором вы сможете проверить ваш контент на наличие дублей. Отчет представлен в виде диаграммы с уникальностью контента внутри сайта.
Дубликаты контента для облегчения поиска задвоенных страниц делятся на четыре категории:
- уникальные;
- очень похожие;
- почти дубликаты;
- полные дубликаты;
- не канонические.

Отчет призван облегчить поиск дублей страниц на сайте. В нем показывается список схожих страниц.
Поиск дублей страниц
Проверка страниц с помощью сервиса «СайтРепорт» позволяет быстро найти дубли и удалить их. Сервис предоставляет информацию в простой и наглядной форме.

Отчет показывает долю дублей тегов и мета-тегов. Выгрузив информацию в csv файл вы сможете проверить уникальность контента страницы с дубликатами.
К примеру, раздел «Теги» содержит результаты проверки сайта путем поиска дубликатов среди тегов и мета-тегов, размещенных на страницах. Полученная информация — это первое, на что необходимо обратить внимание при выявлении задвоенного контента.
В отчете приводятся:
- диаграмма заполнения тегов и количество дублей тегов на страницах;
- схемы динамики, содержания и распределения тегов;
- степень сходства страниц.
Для внесения корректировок и дальнейшего анализа сервис имеет функцию выгрузки данных в CSV-файл.
Проверить сайт на дубли страниц
Следующий шаг — анализ контента. Результаты поиска дублей страниц путем проверки содержащейся информации представлены в специальном разделе.
В отчет входят:
- диаграммы количества и дубликатов контента;
- перечень адресов страниц, вошедших в поиск, с указанием характеристик содержания (грамматических ошибок, объема и уникальности информации);
- сводная таблица полученных данных.
Кроме осуществления вышеперечисленных функций, сервис «СайтРепорт» позволяет проводить множество других видов анализа ресурса. Также доступна генерация xml-карты сайта.
Таким образом, с помощью нашего сервиса вы сможете быстро выполнить поиск и проверку сайта на дубли контента. Получив информацию в виде отчета, вы сможете принять решение по оптимизации контента.
План статьи
Дубли страниц — страницы с одинаковым контентом, доступным по разным URL. Рассмотрим наиболее важные вопросы: как найти дубли страниц, чем вредны дубликаты страниц, частые причины дублирования, удаление дубликатов, примеры.
Чем вредны дубли страниц
Проблема дублей на сайте вызывает у поисковых систем ряд вопросов — какая страница является каноничной, какую страницу показывать в поисковой выдаче и является ли сайт, показывающий посетителям дубликаты страниц качественной площадкой.
Google борется с дубликатами страниц с помощью фильтра Panda, начиная с 2011 года. На данный момент фильтр является частью неотъемлемой частью формулы ранжирования. При наличии Панды, сайт теряет большую часть трафика из поисковой системы.
Яндекс в рекомендациях для вебмастеров рекомендует избегать дублей и предупреждает, что поисковая система выберет лишь одну страницу из дублирующихся в качестве канонической.
Частые причины дублирования страниц
Наиболее частой причиной дублирования страниц является особенность строения CMS, на которых разработан сайт. К примеру, в Joomla есть множество конструкций URL, по которым будет доступен один и тот же контент. Даже в последних версиях WordPress есть вариант доступности контента записей по конструкции site.ru/postID и site.ru/ЧПУ. А в магазинной CMS Opencart: при ЧПУ с включением названии категории — привязанность товара к разным категориям. Некоторые неопытные SEO-оптимизаторы берут за основу один контент и размножают его, меняя всего пару слов в тексте. По такому же принципу работают и дорвеи. Такое дублирование называется частичным и за такое дублирование на сайт также могут быть наложены санкции (Google Panda и др).
Вторая популярная версия дублирования — доступность страниц с www и без (www.site.ru и site.ru). При таком дублировании все версии сайта должны быть добавлены в Google Webmaster Tools, после чего уже избавляться от них.
Третья по популярности вариация дубликатов — наличие контента со слэшем в конце URL и без него.
Поиск и удаление дублей страниц на сайте входит в услугу . Экономьте, заказывая у индивидуального специалиста.
Сервисы и программы поиска
Наиболее быстрый и обычно, точный, способ — найти дубликаты страниц по Title и мета-тегам. Ниже — сервисы и программы, которыми пользуюсь сам.
Сервисы для поиска дублей по Title и мета-тегам:
- Инструмент «Аудит сайта» в сервисе Serpstat (комплексные сервисы для SEO, PPC ~$100/месяц).
- Аудит в сервисе Seotome (за 500 рублей — аудит 1 сайта).
- Другие, если знаете, пишите в комментариях.
Сервисы для поиска частичных дубликатов по контенту:
- Аудит в сервисе Seotome (за 500 рублей аудит 1 сайта). Показывает в процентном соотношении дублирование контента на страницах.
Программы для поиска дублей по Title и мета-тегам:
- Website Auditor от SEO Power Suite (Mac, Windows, Linux, ~$50/единоразово).
- Netpeak Spider (Windows only, $14/месяц).
- Comparser (Windows only, 2000 рублей).
- Xenu (Windows only, free).
Программы для поиска дублей по контенту:
Если знаете подобный софт — напишите в комментарии или по — добавлю в список.
Основные способы избавления от дублей страниц на сайте
- Использовать rel=»canonical», который указывает каноническую версию страницы. Лучший способ избавиться от дублей. При использовании canonical практика показала, что веса дублирующих страниц склеиваются, что хорошо для продвижения.
- Закрыть дублирующиеся страницы от индексации. Можно закрывать конструкциями в robots.txt (как пользоваться robots.txt) или наличием на странице мета-тега .
- Добавить 301 редирект с дублирующей страницы на основную. Подходит при дублировании www/без, слэш на конце/без. Настраивается в файле.htaccess или специальными плагинами.
Как найти дубли страниц: Примеры
Поиск дублей с помощью Serpstat
Поиск дублей с помощью Website Auditor

Поиск дублей с помощью Comparser

а если дубль по контенту, а урл другой, стоит каноникал и в робтсе закрыт, но страница в индексе, как это расценивать?
Каноникал решает проблему с дублированием.
Но если страница попала в индекс, а потом ее в robots.txt закрыли, то робот не может просканировать ее еще раз и пересчитать параметры.
Согласен с предыдущим ответом. Решить проблему можно послав запрос на удаление в поисковой консоли.
Maksim Gordienko
Почему для страниц пагинации рекомендуется использовать canonical, вместо удаления текста + noindex, follow + дописывание в начале Title конструкции "Страница N" на второй и последующих страницах пагинации (а можно еще и prev / next добавить)? Сталкивался с тем, что при размещении canonical товары со второй и последующих страниц плохо индексировались.
Была ли практика использования HTTP-заголовка X-Robots-Tag для запрета индексации страниц, так как при использовании robots часто всплывают такие страницы: http://my.jetscreenshot.com... ?
Каноникал - это всего лишь рекомендация. Еще можно использовать 301-редирект для релевантных страниц. По программам для поиска дублей - рекомендую Компарсер + показывает структуру сайта и еще несколько полезных фич есть. Серпстат - дорогой.
Используй лучше каноникал и прев-нектс и будет супер.
Maksim Gordienko
Сеопрофи, например, пишет что каноникал на пагинации имеет смысл ставить только если есть страница "показать все товары" (да и в рекомендациях Google не приводится пример с пагинацией в её классическом виде). А так, товары (содержимое) на второй странице отличается от первой, ставить каноникал нелогично.
Если нужно только дубли проверить, то лучше использовать специфический софт. Советую Netpeak Spider. Он сейчас активно развивается и проверяет очень много параметров на сайте https://netpeaksoftware.com... . Мы его постоянно используем в работе.
Serpstat хорош тем, что это платформа со множеством инструментов: аналитика запросов, ссылок, аудит, проверка позиций.
Підкажіть, буд ласка, ми видалили з сайту інтернет-магазину певні категорії, створили нові, в видалених категоріях були товари і ми цим товарам прописали нові категорії - після цього в нас створилися нові сторінки товарів вже де в урл нові категорії і утворилися дублі. Як краще зробити? Зробити урл товару статичним (а не динамічним) і з нових створених сторінок поставити 301 редиректи на старі? (інтернет-магазин існує 6 місяців) чи має змінюватися урл товару якщо змінили категорію? (в структурі урла товару є назва категорії).
1. Щоб уникнути дублювання URL товарів ми зазвичай поміщаємо їх в одну папку /product/, а категорії задаються в меню і хлібних крихтах.
2. Якщо нема можливості так зробити, то виберіть один із варіантів.
2.1. Використовуйте rel canonical на основную сторінку товару. Скоріше всього, в вашому випадку це нова сторінка, тому що нова категорія вказана в URL. Але ви самі вибирайте головну сторінку.
2.2. Використовуйте 301 редирект на головний URL. При цьому на сайті не повинно бути посилань на старі URL, тобто посилань на 301 редирект.
3. URL товарів краще робити статичными або User Friendly.
4. "чи має змінюватися урл товару якщо змінили категорію? (в структурі урла товару є назва категорії)."
Якщо нема можливості не задавати категорію в URL (як в п.1.), то при кожній зміні категорії в URL її теж треба міняти і налаштовувати 301 редирект на нову адресу.
Дякую за таке обширне пояснення)
Подскажите, как избежать дублей контента. Есть 33 позиции однотипного товара https://delivax.com.ua/pack...
Писать к каждому уникальное описание - сложно и вроде как не нужно. Но из-за того, что описание дублируется, из 33 позиций в индексе висит только 5. Стоит ли переживать по этому поводу и что с этим делать?
Читайте также...
- Скачать клоун фиш для скайпа на русском языке Установка программы "Клоун-фиш"
- Как можно заработать много денег — основные способы много заработать
- Лучший просмотрщик для Mac, или как просматривать фото на macOS – лучшие приложения Как включить слайд шоу на макбуке
- Почта Швеции Direct link sweden post доставка из китая